Cet article explique le développement web en étudiant son commencement et son évolution. Il ne s’agit pas d’une chronique sur l’évolution du web mais plutôt de l’histoire des besoins qui ont amené à l’évolution du web, afin de mieux comprendre cette technologie.
Tout a commencé avec l’information. Les êtres humains ont toujours eu besoin de trouver des moyens de se partager des informations. Comme vous le savez, avant Internet, les informations étaient échangées via les courriers, les journaux, la radio et la télévision.
Ces moyens de communication ont de nombreux inconvénients : c’est ce qui a permis à Internet de s’imposer.

L’article sera publié en deux parties :
- Côté client : architecture d’une page et styles
- Côté serveur : formulaires et bases de données
Commençons par ce qu’il se passe côté client.
Partie I
Côté client : architecture d’une page et styles
1. Qu’est-ce que le web ?
Imaginez que vous puissiez publier une information qui soit accessible à tous et qui soit lisible par toute personne intéressée par cette information ? C’est exactement ce que permet le web. L’information est stockée sur un serveur web, et les gens peuvent lire cette information en utilisant des clients (les navigateurs web). C’est ce qu’on appelle une “architecture client-serveur”.
Pourquoi HTTP ?
Vous avez probablement déjà vu ces quatre lettres dans la barre d’URL de votre navigateur. Elles signifient Hyper-Text Transfer Protocol. Littéralement : “protocole de transfert hypertexte”. HTTP est donc un protocole de communication client-serveur utilisé spécifiquement pour le web.
Initialement, l’information était enregistrée uniquement au format texte — c’est pourquoi le nom Hyper-Text Transfer Protocol est resté même si, maintenant, différents formats d’information (texte, média, fichier, etc.) sont échangés via ce protocole.
HTTPS, Hyper-Text Transfer Protocol Secured, est la version sécurisée de HTTP.
2. Comment l’information est-elle conservée, récupérée et sauvegardée ?
HTML
Le fichier HTML est la façon la plus simple et durable de stocker des informations sur le web. Pour mieux comprendre, prenons l’exemple d’une entreprise publiant ses prix sous la forme d’une liste de produits (avec un prix et une date de validité), afin que ses fournisseurs puissent les télécharger et/ou les voir. Cette liste est stockée dans un fichier HTML, placé sur un serveur, et elle pourra être vue en utilisant un navigateur web. Le navigateur demande ce fichier au serveur (requête), le serveur le lui fournit et ferme la connexion.
HTML est le langage de balisage standard utilisé pour créer des pages web. Concrètement, c’est un simple fichier texte, avec des balises (tags) qui aident le navigateur à comprendre comment afficher l’information.


CSS
Le CSS (Cascading Style Sheets ou feuilles de style en cascade) est un langage de style utilisé pour décrire la présentation d’un document écrit dans un langage de balisage. Le HTML permet de faire une mise en page de base, mais il vaut mieux utiliser le CSS pour appliquer des styles plus complexes et sophistiqués.
Une application web contient de nombreuses pages, dynamiques ou statiques. Si nous utilisons les balises HTML pour styliser l’information, nous allons devoir le répéter sur toutes les pages. Imaginons que nous souhaitons changer la couleur d’arrière-plan : nous devrons alors éditer le HTML de chacune des pages du site.
À la place, nous pouvons utiliser le CSS pour stocker nos définitions de style à un seul emplacement, et y faire référence dans chaque page HTML. En éditant le fichier CSS, nous allons changer la couleur d’arrière-plan sur toutes les pages qui pointent vers cette feuille de styles.
Le CSS permet bien sûr de faire bien plus que donner une couleur d’arrière-plan : il permet notamment de changer la couleur de toutes sortes d’éléments, polices de caractères, mises en page… Et plus encore !
Nous avons mis des styles CSS sur notre exemple précédent. Disons que nous utilisons des tableaux sur différentes pages, mais tous utilisent les mêmes styles CSS. Nous pouvons donc déplacer toutes ces définitions de style dans un fichier à part.
Les styles CSS sont toujours appelés en haut du document HTML, entre les balises <head>.



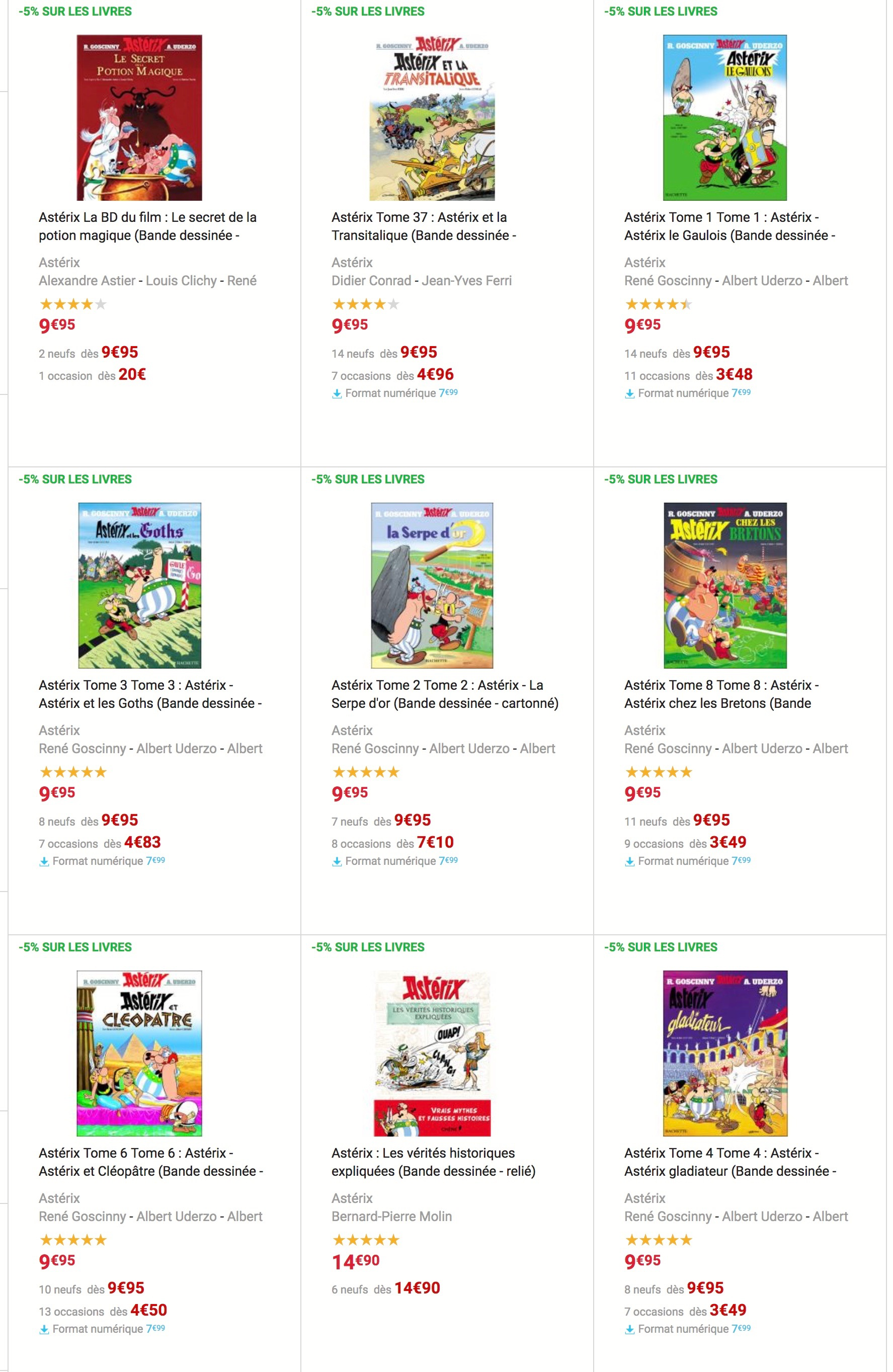
Ci-dessous, un exemple de liste de produits sur le site fnac.com.
Le CSS permet de transformer complètement le HTML de base et de faire des mises en page complexes : ici, le tableau de produits contient une image centrée ; le titre et les autres informations de la BD ont des styles différents permettant de les hiérarchiser ; les prix sont colorés en rouge, etc.
JavaScript
Le JavaScript est le troisième pilier du web aux côtés du HTML et du CSS. Il est utilisé pour rendre les pages web interactives. Pour comprendre le JavaScript (JS), il faut commencer par savoir ce qu’est le DOM.
Le Document Object Model (DOM) est une interface de programmation normalisée qui transforme le document HTML en une arborescence. Les noeuds de chaque document sont organisés dans cette arborescence — appelée “arbre DOM” (DOM tree) — dont le noeud le plus haut est appelé Document Object.

Extrait de l’arborescence DOM (Source : Wikimedia Commons)
Lorsqu’une page HTML est rendue dans le navigateur, le navigateur télécharge le code HTML dans la mémoire locale et crée un arbre DOM pour afficher la page à l’écran.
En utilisant le JS, nous pouvons manipuler l’arborescence DOM de plusieurs manières :
- modifier l’arbre DOM en ajoutant, modifiant et supprimant tous les éléments et attributs HTML de la page ;
- changer tous les styles CSS d’une page ;
- réagir à tous les événements existants sur la page ;
- créer de nouveaux événements dans la page (et réagir à tous ces nouveaux événements).
Continuons avec notre exemple de la liste de prix, en ajoutant une autre colonne — Special Price — dont le contenu est masqué par défaut. Nous allons le montrer une fois que l’utilisateur aura cliqué sur un bouton. Techniquement, nous allons utiliser un événement de clic (click event) attaché à un élément d’ancrage (anchor tag) et changer le texte existant de l’élément web. En d’autres termes, nous allons manipuler le DOM. Pour ce faire, nous devons utiliser le langage de script accepté du navigateur, qui est… toujours le JavaScript.
Pour information : le JavaScript se place généralement à la fin du fichier HTML, juste avant la fermeture de la balise </body>.



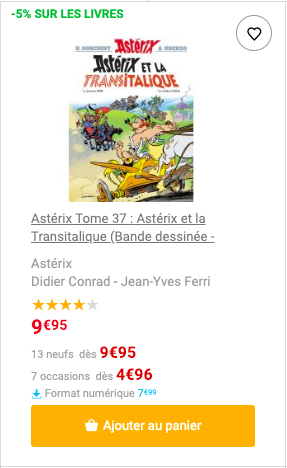
Sur le site fnac.com, le bouton “Ajouter au panier” apparaît au survol du produit.
Ça, c’est fait grâce au CSS.
Au clic sur le bouton, une pop-in apparaît (sans rechargement de la page) :

Et ça, c’est fait grâce à JavaScript : un événement “clic” a été placé sur le bouton et, à l’exécution de cet événement, une fonction chargée d’ouvrir la pop-in est appelée.
Le mécanisme d’ajout au panier est quant à lui géré côté serveur.
# Traduction de l’article Understand Web Development in Less than 1 Hour, par Shaik Ismail
Audrey Guénée, DEV-FRONT @UX-Republic
