
L’Atomic UX Research est une approche de Daniel Pidcock, inspirée par l’Atomic Design et permettant d’organiser les données issues de la recherche utilisateur. Ces données peuvent alors être décomposées, classées, connectées et croisées pour identifier des tendances. Pidcock l’introduit ainsi : “a new way to organise UX knowledge in an infinitely powerful manner.” c’est-à-dire une nouvelle façon d’organiser la connaissance UX d’une manière infiniment puissante.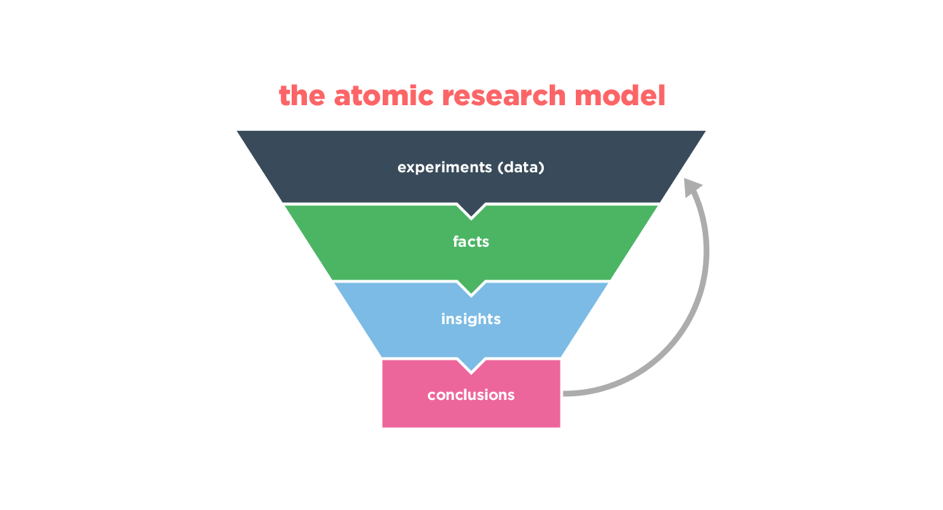
Modèle de l’Atomic Research de Daniel Pidcock
Pidcock décompose ce modèle de la manière suivante : les expériences «ce que l’on a fait…», les faits «ce qui nous apprend que…», les insights «ce qui nous fait penser que…», les conclusions «… donc on va faire ça.» Les conclusions, ou recommandations UX, sont à leur tour testées avec des nouvelles expériences dans une boucle itérative. Cette manière de découper la donnée et de l’interconnecter présente de nombreux avantages par rapport aux méthodes d’analyse classiques, ou chaque test va être traité indépendamment des autres.
#1 Appliquer l’Atomic Research
Mais avant de parler de ces avantages, parlons de la mise en place de cette méthode. Les outils émergent progressivement : malheureusement la version beta du logiciel de Daniel Pidcock Glean.ly est toujours en accès limité. Des alternatives un peu différentes existent déjà telles que Dovetail et Consider.ly, tandis que d’autres outils plus flexibles sont détournés pour cet usage, comme Notion ou Airtable.
Tous permettent de rentrer des données, des faits associés à des projets, des expériences.
On peut alors déduire des insights connectés à un ou plusieurs faits émanant d’une ou de plusieurs expériences. De la même manière, les insights aboutissent à des conclusions. En plus des connexions entre chaque entrée, ces outils permettent de les tagguer, par exemple par sujet, composant, device, pays, priorité, etc. L’outil peut s’utiliser à la place ou en complément d’une prise de note lors de tests utilisateur par exemple, mais il permet surtout de constituer une base de données de notre connaissance UX.
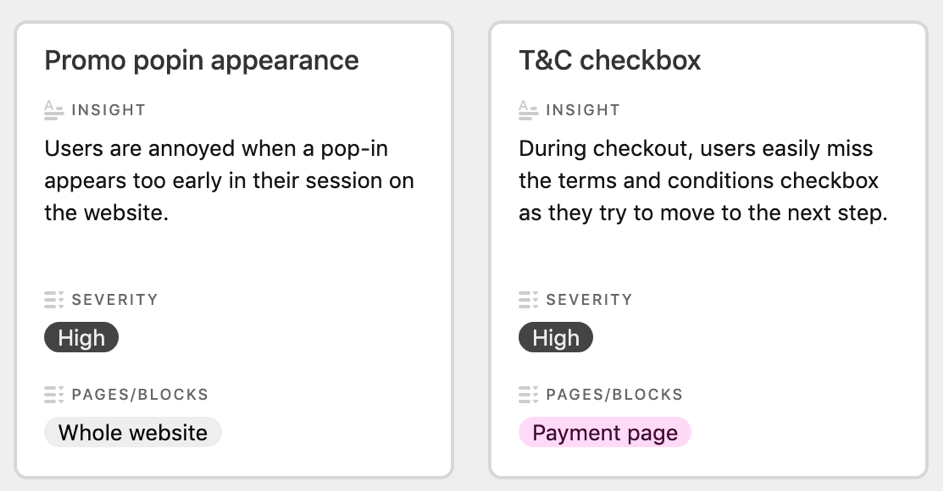
Insights utilisateurs créés sur Airtable
#2 Les bénéfices de l’Atomic Research
- Les données ne sont plus éparpillées
Avec nos méthodes classiques, les données de nos équipes UX vont se retrouver dans une multitude de logiciels et de documents (texte, tableur, présentations, captures d’écran…), hébergés à différents endroits (Teams, Sharepoint, Drive, E-mails, Slack…). Si on veut croiser avec des données du support client, Google Analytics, avis sur les réseaux sociaux, etc. les entrées se multiplient encore davantage. Avec l’Atomic UX Research, et un travail de fond de saisie de la donnée UX ou utilisateur élargie, nous pouvons filtrer notre base de données pour récupérer tous les insights et les conclusions sur un sujet donné, et ces entrées s’appuient sur des faits vérifiables que l’on peut consulter. En prenant l’exemple d’un site e-commerce, tous les insights utilisateur qui portent sur la page produit peuvent être appelés en quelques clics, tandis que par le passé il aurait fallu lire plusieurs rapports, présentations, chaînes d’e-mail pour retrouver une partie de la donnée.
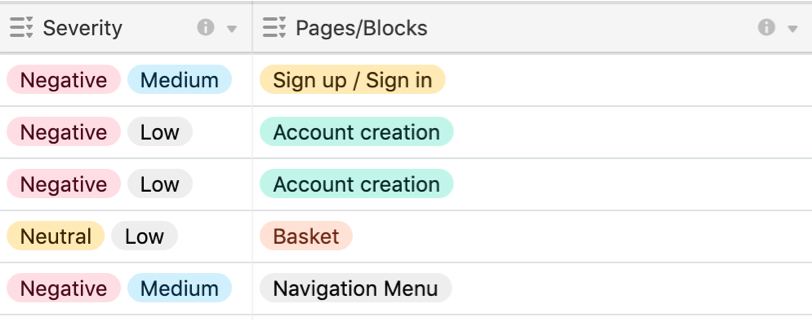
Colonnes et tags sur Airtable permettant de trier et filtrer les entrées
- Les données ne sont plus oubliées
Nos rapports finissent toujours par prendre la poussière, surtout quand les recommandations UX ont été implémentées. Pourtant, certains apprentissages, insights ou guidelines, peuvent restent pertinents pour les projets à venir. Un autre phénomène courant : durant un test ou un entretien utilisateur, nous allons collecter de la donnée « hors-sujet », qui ne va pas immédiatement nous intéresser. Sans l’Atomic UX Research, cette donnée risque d’être occultée. Elle sera peut-être, par souci d’exhaustivité, intégrée à un rapport, mais si nous n’y associons pas d’action sur le moment nous ne penserons plus à aller la chercher quand le sujet deviendra pertinent. Saisie dans une base de données et tagguée, nous sommes sûrs de la retrouver au moment où nous en aurons besoin.
- Nous gagnons du temps sur la recherche utilisateur
La consultation de notre base de données peut devenir l’une des premières étapes de la recherche utilisateur au début d’un projet. Elle permet de faire une revue de ce qui a déjà été entrepris et appris sur nos utilisateurs. Pour les plus structures importantes comprenant plusieurs équipes d’UX Researchers, d’AB testeurs, etc., elle permet également de s’assurer qu’un test n’a pas déjà été réalisé et éviter les doublons entre équipes.
- Les résultats des études utilisateur sont partagés
Une base de données des résultats de tests utilisateur entraîne une plus grande transparence du travail des équipes UX. Elle participe directement de l’évangélisation sur les approches centrées utilisateur et facilite également la communication entre les UX designers et les autres équipes de l’organisation.
#3 Quelques challenges
- Onboarder nos collègues UX sur l’outil
Pour que l’implémentation fonctionne, il faut convaincre nos collègues d’utiliser l’outil, ou de mettre à disposition leurs données pour qu’une personne prenant le rôle de secrétaire se charge de les saisir. Il faut s’assurer que le paramétrage et les conventions de saisie et de tags conviennent à chacun, pour obtenir une base homogène que nous pouvons filtrer sans perdre de l’information.
- Onboarder nos collègues non UX
Nous retrouvons les mêmes challenges qu’avec nos collègues UX, avec la contrainte supplémentaire de paramétrer l’outil de sorte à ce que tout type de donnée concernée puisse être entré en parallèle des données émanant des études UX. Tout un travail d’évangélisation est aussi nécessaire pour que les équipes prennent le réflexe de consulter l’outil quand elles en ont besoin.
- Utiliser systématiquement la base de données
Saisir la donnée à chaque test, afin de ne pas prendre de retard et d’éviter l’obsolescence de la base,
Prévoir des points de restitution avec les autres équipes pour collecter l’intimité client et saisir de la donnée utilisateur qui émane d’autres sources,
Acquérir des automatismes : toujours consulter la base a minima en première phase de nos projets.
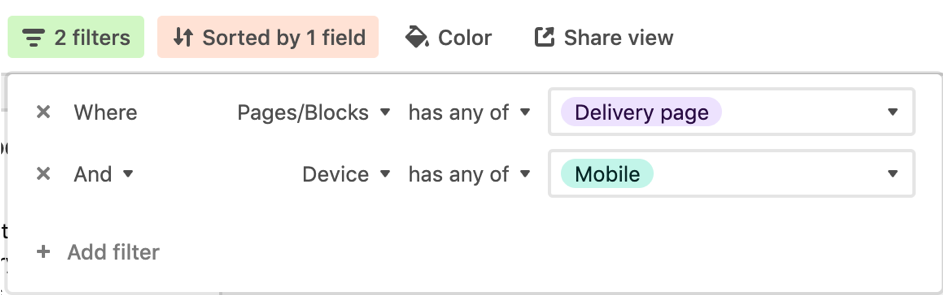
Fonction de filtre sur Airtable
Appuyer notre expérience d’UX Researcher
Au fur et à mesure des tests et de notre carrière, nous avons l’impression de savoir des choses sur les utilisateurs. On anticipe les éléments qui entraîneront de la friction ou seront facilement pris en main, parce que nous l’avons constaté à plusieurs reprises. Nous nous appuyons sur ces informations : elles font partie de notre expérience, notre expertise. Mais nous ne pouvons pas tout retenir, nous oublions le contexte précis dans lequel cette connaissance a émergé.
On peut envisager, de la même manière qu’une base de données à l’échelle d’une équipe ou d’une entreprise, une base de données individuelle, des insights généraux sur les utilisateurs qui sera remise en question et évoluera avec notre pratique. Il est possible d’externaliser, renforcer et appuyer notre expertise par de la donnée concrète, dont on garde trace, grâce à des outils dont les versions gratuites sont souvent suffisantes pour un usage personnel.
# Take Away
L’Atomic UX Research est une méthode nouvelle, les retours d’expérience sont encore rares et l’implémentation présente plusieurs challenges. Néanmoins, ses apports sont évidents et immédiats :
- Des données centralisées, que nous pouvons facilement croiser,
- Un outil de communication et d’évangélisation,
- Des insights et recommandations qui sont connectées à des faits et à un contexte précis.
Elle vaut le coup d’être connue et d’être testée.
Pour aller plus loin
https://blog.prototypr.io/what-is-atomic-research-e5d9fbc1285c
https://medium.com/@tsharon/democratizing-ux-670b95fbc07f
https://uxstudioteam.com/ux-blog/ux-research-system/
À demain pour de nouvelles surprises sur notre calendrier de l’Avent UX-Republic !
Marie EUZEN, UX Designer @UX-Republic
