Préambule
On entend de plus en plus parler de l’utilisation grandissante du concept Redux avec Angular (2+). En cherchant plusieurs articles pour m’aiguiller sur le sujet, je me suis rendu compte que bien trop peu sont accessibles dans notre belle langue de Molière. Cet article a donc pour but de vous faire comprendre Redux, et son utilisation avec un framework qui n’est de base pas son domaine de prédilection. Si vous utilisez Angular et n’êtes pas familier avec ce concept, vous êtes au bon endroit.

Pré-requis
Cet article est destiné à des développeurs ayant l’habitude d’utiliser Angular sans pour autant avoir une idée claire de ce qu’est Redux. Les concepts tels que les Observables, les notions élémentaires de Typescript et les Components seront considérées comme acquises. La connaissance de la programmation Fonctionnelle est un plus.
Introduction
Redux est une architecture qui a pour objectif de concentrer à un seul endroit l’état de votre application. Des actions vont être dispatchées par des événements, qui vont à chaque fois reprendre l’état précédent, en modifier une partie, et en renvoyer un nouveau qui sera utilisé pour gérer vos données.
Ce n’est pas très clair ? Pas de soucis, le but de cet article est de démystifier un concept d’apparence compliqué mais qui se révèle simple et logique.
Avant de rentrer dans le vif du sujet, je souhaiterais insister sur le fait que Redux, très souvent employé avec React, n’est en rien dépendant de ce dernier. Il est plus que temps que l’on comprenne les bienfaits d’une architecture très pratique à utiliser avec tout framework/librairie orientée composant, et Angular en est un parfait exemple.
Quels sont les problèmes liés à Angular qui peuvent être résolus par nouvelle cette gestion des données de l’application ?
Les variables partagées par différents composants de différents niveaux
Dans un composant Angular de manière générale, il est rare d’avoir des variables en readonly pour autre chose que les constantes ou les Observables de service. Les variables directement affichées dans le composant sont également modifiées par ce même composant. Mais là où l’on peut avoir un vrai problème, c’est lorsque ces variables sont passées en Input à un sous-composant, et qu’elles sont modifiées par ce sous-composant. C’est possible et ça fonctionne car le data-binding d’Angular est fait pour ça. Il devient cependant très difficile de le tester, et le code peut avoir des effets de bord.
Imaginons une arborescence telle que :
Component0
├── Component1
└── Component2
└── Component3
On possède une variable que l’on veut commune aux composants 1 et 3. Alors, on est obligé de déclarer cette variable comme propriété du Component0 , uniquement pour l’avoir à jour dans le Component2 ainsi que dans le Component3. On va devoir mettre un output dans le composant 1 si on veut modifier la variable suite à un événement. Et faire de même, non seulement dans le Component3, mais également dans le Component2 pour remonter jusqu’au Component0 avec des EventEmitter.
Beaucoup de code, pour simplement modifier une variable utilisée à 2 endroits d’une même page.
Evidemment, Angular embarque déjà des solutions que l’on pourrait utiliser dans le cas présent. L’utilisation notamment des services, dans lequel on stockerait la variable partagée. Si on voulait qu’elle soit bindée dans les deux composants, c’est-à-dire qu’elle se modifie en temps réel dans le Component1 lorsqu’elle a été changée dans le Component3, alors on devrait utiliser des paradigmes de programmation réactive, notamment les Observables avec RXJS. C’est faisable, et beaucoup d’applications fonctionnent ainsi, mais cela peut devenir difficile à maintenir lorsque le pattern se répète régulièrement, à plusieurs endroits de l’application. Cependant cette idée n’est pas à écarter totalement, car elle va apporter une base à notre solution.
Les données bindées sont très volatiles et le debug peut être compliqué
Les données peuvent changer sans arrêt et, à moins de travailler constamment en immutable, suivre les changements de valeurs d’un objet peut devenir compliqué. Il est aussi difficile de garder un historique des actions et événements effectués depuis un instant T. Redux apporte aussi une solution à ce niveau-là avec son “Time-travel debugging”. Redux garde à chaque création d’un nouveau state une copie de sa version précédente, et le tout est disponible dans les Dev Tools via l’extension
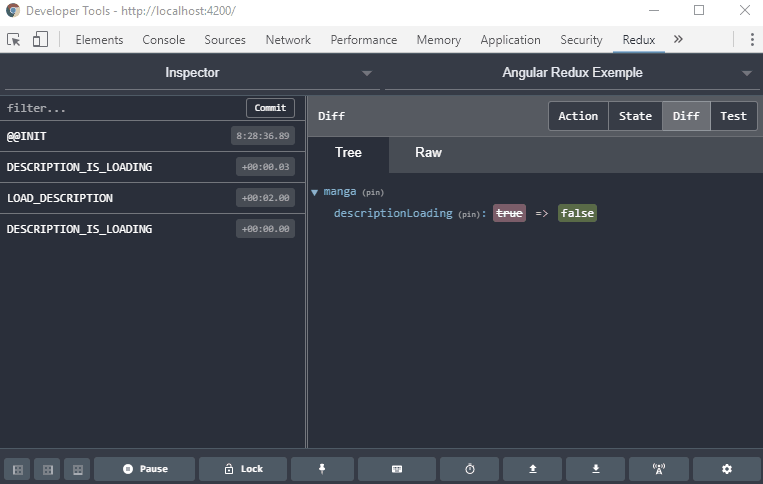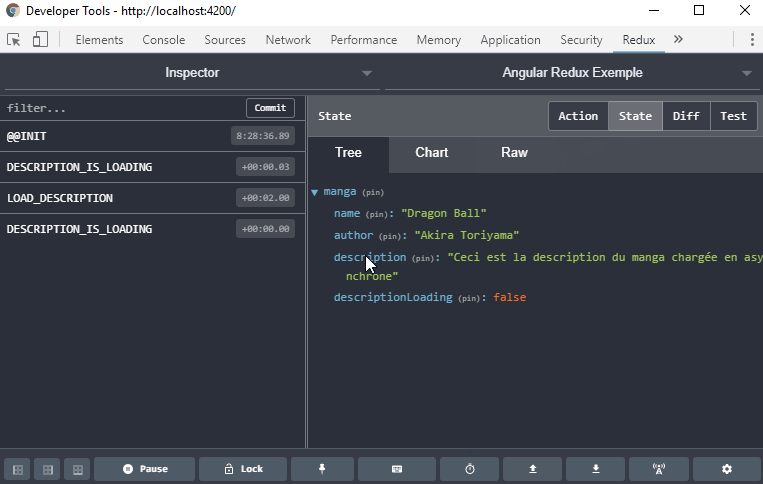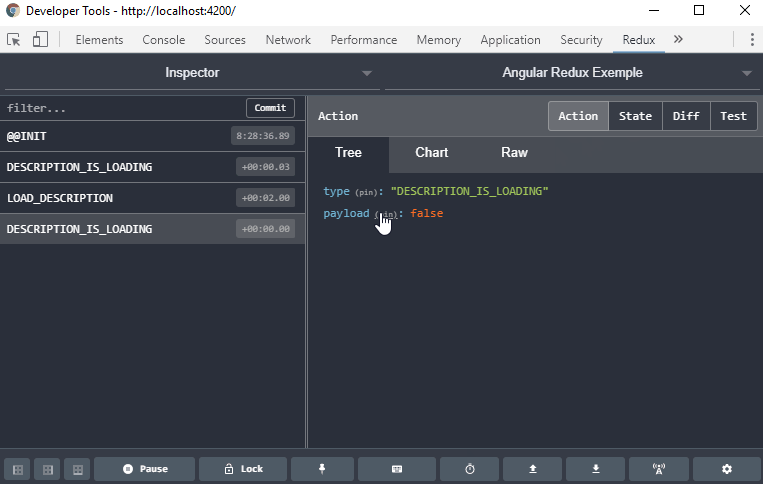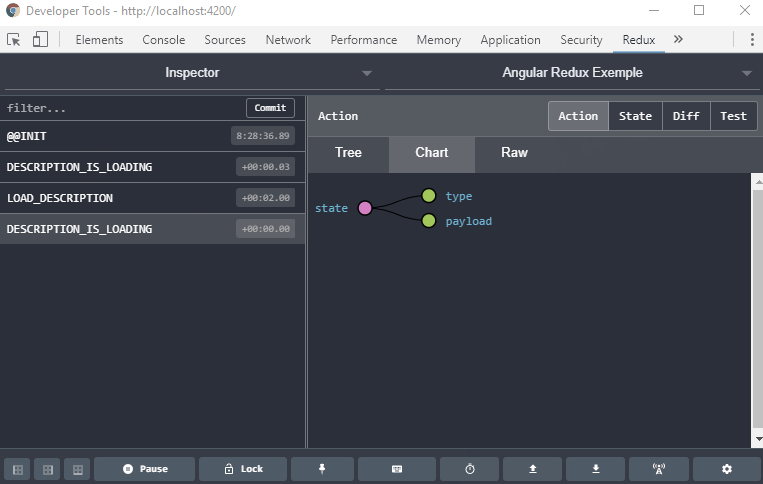
Il peut être difficile d’organiser le code qui modifie les variables de manière pure.
Ici, on rentre vraiment dans une partie de l’explication de la programmation fonctionnelle, mais une solution apportée par ce paradigme est le concept de “fonction pure”. Une fonction pure possède un ou plusieurs arguments, ne modifie aucune variable extérieure à son scope, et retourne une valeur qui se sera toujours la même avec les mêmes arguments. C’est assez simple en théorie, et pas toujours en pratique.
Si vous souhaitez plonger plus en profondeur dans l’explication et la compréhension du paradigme de programmation fonctionnelle, je ne peux que vous conseiller un article de Yoan Ribeiro sur le sujet.
Par ailleurs, l’utilisation d’Angular nous amène souvent à faire de la POO plutôt que de la programmation fonctionnelle, dans le sens où l’on modifie les données du composant (qui est une classe) qui sont par définitions externes aux méthodes du composant.
Un peu de théorie avant la pratique
Maintenant que nous avons soulevé quelques points inhérents au développement avec Angular et qui peuvent être simplifiés avec Redux, nous allons essayer de bien comprendre le pattern, en architecturant une application Redux basique.
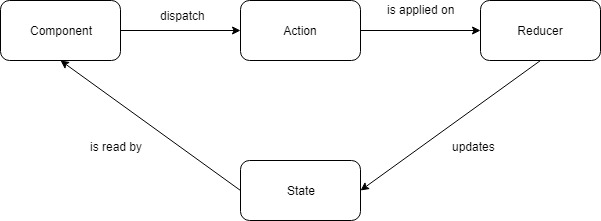
Vous verrez parfois parler de Store, parfois de State. Les deux mots recouvrent globalement le même sens, à savoir l’Etat de l’application et sa structure de données.
Ce schéma est très simple. Depuis notre composant, on va dispatcher une action. On peut traduire cela par le simple fait d’envoyer un appel, un événement qui va lui même appeler une fonction.
Ensuite cette action va être appliquée sur un reducer qui va agir sur le state de l’application. C’est finalement ce même state qui va être lu par le(s) composant(s) dans l’UI.
En deux phrases et un simple schéma, on a pu résumer assez facilement le concept. Mais évidemment, les actions, les reducer et le state on tous chacun un rôle. Et même s’il peut sembler y avoir beaucoup de code et de fonctions pour faire peu de choses, il ont chacun une grande importance.
Comme on peut le voir, le flot devra toujours être unidirectionnel, et c’est un point important qui va servir de pierre angulaire à notre architecture. Les actions utilisateurs vont passer par le composant qui dispatchera des actions. Ces actions vont être dispatchées aux reducers, nos fonctions pures qui retourneront un nouveau state pour l’application.
On parlait plus tôt d’un souci d’effet de bord en modifiant des variable partagées par plusieurs composants. Redux apporte une vraie solution à ce niveau-là en se plaçant sur le concept de la programmation fonctionnelle, et non sur de l’orienté-objet. Une minimisation des effets de bords, chaque composant quel qu’il soit ne va agir que sur l’état qui lui est nécessaire. On va dispatcher une action pour mettre à jour une propriété du state. Ensuite à chaque endroit où cette propriété sera utilisée sous forme de variable dans un composant, elle sera bindée et donc modifiée, le tout en une action propre qui n’aura modifiée que cette propriété.
Exemple d’un reducer
const reducer: Reducer<AppState> = (state: AppState, action: Action) => {
switch (action.type) {
case "IS_LOADING":
return {
...state,
isLoading: action.payload
};
default:
return state;
}
};
Place à la pratique
Voici un schéma un peu plus compliqué qui traduit un cas réel d’utilisation dans le cadre du développement d’une application.
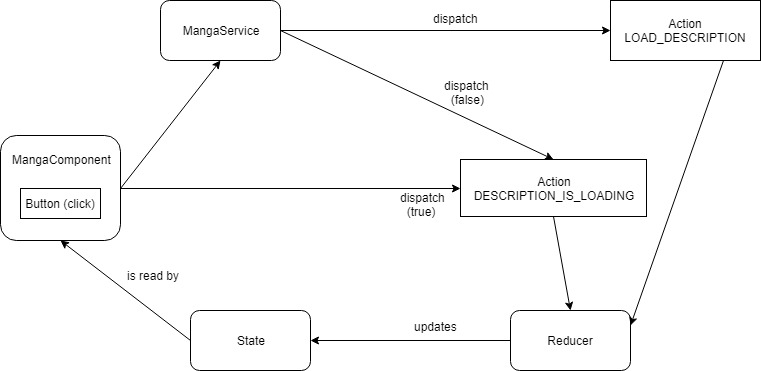
NDD: un payload est le nom donné à une variable de n’importe quelle type qui va être envoyée dans l’action et utilisée par le reducer.
Prenons un cas où l’on construit une application qui ressemble à un blog, mais qui traite de mangas (pour changer des articles).
On va avoir un composant qui va afficher les données d’un manga via son ID (présent dans l’URL). Imaginons que le titre du manga, son auteur et son nombre de tomes sont des données chargées à l’affichage de la page, mais pas sa description. Celle-ci étant très longue, il faut cliquer sur un bouton pour l’afficher et donc, la charger.
Au clic sur ce bouton, il va se passer plusieurs choses. Notre composant va dispatcher une action qui va charger la description du manga via la fonction loadMangaDescription(). Cette fonction va tout d’abord dispatcher l’action DESCRIPTION_IS_LOADING avec un payload à true. On va vouloir montrer à l’utilisateur que l’information est en train de charger. On peut par exemple, tant que cette valeur est à true, afficher un spinner. Le composant va donc récupérer cette valeur du State, qui a été mis à jour par le reducer appelé par l’action DESCRIPTION_IS_LOADING.
Une fois que de manière totalement synchrone, on a mis à jour notre State pour dire que la description est en train de charger, on peut passer à la suite. Le composant a non seulement dispatché cette action, mais il a également appelé un service qui lui, va aller chercher la description via un call HTTP. Qui dit HTTP ici dit asynchrone, donc on ne sait pas quand la réponse va arriver. C’est généralement pour ça que l’on affiche des spinners, comme dans cet exemple.
Au retour de la requête, le service va retourner le résultat au composant qui va enfin pouvoir lancer les deux actions suivantes (en se branchant au résultat par Promise ou Souscription). Le composant va donc pouvoir dispatcher une nouvelle fois l’action DESCRIPTION_IS_LOADING avec cette fois un payload à false.
Mais ce n’est pas tout. Le but de notre manoeuvre, depuis le composant, est de récupérer la description du manga. C’est bien de mettre un spinner pendant le chargement et de le supprimer une fois les données reçues, mais encore faudrait-il utiliser ces données. Pour ça, on va dispatcher une deuxième action à la suite de la première qui met le loading à false, qui sera LOAD_DESCRIPTION. Cette action va contenir en payload les données que l’on souhaite envoyer au reducer puis retrouver dans le state. Ce sont ces données qui vont ensuite être affichées sur l’UI, fournies au composant.
Le code produit pour cet exemple peut être retrouvé sur ce repository Github pour avoir une compréhension plus profonde de l’utilisation de Redux au-delà de la théorie et des schémas. Il est relativement simple et correspond à un startup de NgRedux, avec surtout l’essentiel pour que l’architecture fonctionne.
Les Epics
Un autre concept apporté par Redux est celui des Epics. Dans le cas précédent, on aimerait bien par exemple ne pas être obligé de spécifier qu’une fois le call Service effectué et l’action dispatchée, on souhaite aussi que le loader disparaisse en dispatchant une nouvelle action. Si on devait dispatcher à plusieurs endroits l’action qui remplit la donnée, on serait alors obligé de dupliquer le code pour faire disparaître le loader. C’est là que rentrent en scène les Epics. Une Epic est une fonction qui va être déclenchée par un reducer et qui va prendre un stream d’actions pour retourner un autre stream d’actions. Dans notre cas, il suffirait de dire qu’à chaque fois que l’action LOAD_DESCRIPTION est dispachée, on veut aussi dispatcher l’action DESCRIPTION_IS_LOADING avec le payload à false. Simple et efficace, pas de duplication de code ni de cas supplémentaire à gérer.
Plus d’informations sur le concept des Epics et leurs cas d’utilisation :
– https://medium.com/kevin-salters-blog/epic-middleware-in-redux-e4385b6ff7c6
– https://redux-observable.js.org/docs/basics/Epics.html
Angular-Redux
Jusque-là, une question demeure toujours. Nous savons bien comment écouter des événements sur le composant pour dispatcher nos actions. Nous savons comment y brancher un service si l’on a besoin de données asynchrones, et comment dispatcher efficacement nos actions sur les reducers pour que les changements de données dans le state ne s’entrechoquent pas. Sauf qu’une fois que nous avons mis à jour notre state, la manière de récupérer les éléments est encore un peu floue.
Comment savoir quand une variable a changé de valeur ? Et comment utiliser cette nouvelle valeur dans notre composant ?
C’est pour répondre à ce genre de questions qu’ont été créées des librairies comme Angular-Redux. Il s’agit d’un middleware qui va nous permettre d’agir et de récupérer des éléments de notre state de manière statique ou dynamique. Voici un exemple de code pour récupérer notre description de manga de manière dynamique.
import { select } from '@angular-redux/store';
import { Observable } from 'rxjs/Observable';
import { MangaState } from '../store/state';
@Component({
selector: 'app-manga',
})
export class MangaComponent {
@select(['manga']) readonly manga: Observable;
constructor() {}
}
Tiré du code provenant du repository ci-dessus et simplifié, ce code nous permet d’avoir un aperçu de la récupération de nos données du store.
Le premier mot-clé de la ligne est le @select qui est un décorateur fourni par angular-redux et qui nous permet de récupérer notre élément manga du store et d’en faire un Observable. Ce à quoi correspond le type de notre variable, en prenant en entrée l’interface MangaState qui correspond au type de notre objet.
A partir de là, il va être simple d’afficher les données en HTML. Il y a cependant un petit changement à opérer pour gérer l’Observable.
<div *ngIf="manga | async; let manga">
Nom du manga : {{ manga.name }}
Auteur du manga : {{ manga.author }}
<div>LOADING DESCRIPTION</div>
<div>{{ manga.description }}</div>
</div>
Comme on peut le voir, il faut gérer l’Observable de manière asynchrone. L’Observable est un flux qui peut avoir des valeurs fixes à un instant T, mais pour afficher ces valeurs dans le HTML, il faut mettre un pipe | async qui va automatiquement récupérer la dernière valeur. Seconde remarque, derrière le pipe, on peut créer une variable locale pour ensuite ne pas avoir à faire un pipe async pour chaque valeur à afficher (ce qui serait possible). Ainsi le {{ manga.name }} va en réalité afficher la propriété name de la variable locale manga créée, et non celle de l’Observable.
Retour d’expérience
Ayant travaillé sur des applications Angular from scratch avec et sans Redux, je dirais qu’il y’a un tour de main à prendre pour “penser Redux” mais qui arrive assez vite. Comme en passant d’un langage objet à un langage fonctionnel, il faut s’habituer à coder différemment. Mais le jeu en vaut vraiment la chandelle, et l’association de Redux + typage + tests est un combo gagnant pour une application extrêmement solide, facilement débuggable et maintenable. Evidemment, sa mise en place reste plus longue car un Store doit être bien pensé en fonction des besoins de l’application. La séparation des données entre différents reducers peut également être un point qui va déterminer la maintenabilité en fonction de la réutilisation de ces reducers par différentes pages. Redux est une architecture ouverte dans laquelle vous pouvez même rajouter des patterns correspondant à vos besoins, comme de remplacer les Epics par un autre système de Dispatchers qui auront seuls la responsabilité de faire le dispatch d’actions par exemple.
Conclusion
On s’aperçoit qu’une architecture comme Redux peut s’interfacer dans tout type d’application. Il suffit simplement de bien comprendre l’utilité du pattern pour la gestion des données et de l’état global de votre application.
Il faut simplement penser aux extras pour l’intégrer dans Angular, tel que Angular-Redux pour gérer le binding entre les variables de composants et le state global.
L’utilisation de Typescript prend tout son sens notamment via le typage du store et des données qu’il contient, que l’on peut retrouver dans les reducers ainsi que les actions, et même les Observables dans les composants (voir le code du repository). On a donc sur tout le code une sécurité apportée par le typage pour éviter au maximum les erreurs.
Autre point important : Redux n’est pas magique. Evidemment, il faut se rendre compte que Redux n’est rien de plus qu’une architecture ajoutée à votre application, mais qui ne gomme pas comme par enchantement tous les problèmes de patterns que votre application peut déjà avoir. Même si la librairie apporte une forte solution à la gestion des données de l’application il n’en reste pas moins que sa mise en place nécessite du temps. Il faut bien réfléchir à la structure des données et à sa normalisation, car cela aura un impact important sur l’architecture des actions, du store, et des reducers. Il faut prendre le temps de typer et tester ces données ainsi que les fonctions qui les modifient pour garder une application saine, fonctionnelle et sans surprises.
Ecrit par Guillaume Barranco
